




去标识化是保护数据的一种常用的安全技术措施,也是企业履行个人信息保护义务的方式之一。《中华人民共和国个人信息保护法》(下称《个保法》)第五十一条第三项规定了企业应对个人信息采取相应的加密、去标识化等安全技术措施,同时第七十五条明确了去标识化的定义。《个保法》生效前,《深圳经济特区数据条例》(下称《深圳数据条例》)明确规定提供数据和处理敏感个人数据时应实施去标识化处理;国家信标委发布的GB/T 35273-2020 《信息安全技术 个人信息安全规范》(下称《个人信息安全规范》)和GB/T 37964-2019 《信息安全技术 个人信息去标识化指南》(下称《个人信息去标识化指南》)均给出了去标识的定义和要求,后一个国家推荐性标准则结合业内最佳实践,为去标识化的实施提供了详细的指导和参考。
北源数据合规团队于2021年协助多家企业完成数据安全合规评估和优化工作,其中关于个人信息的去标识化,企业仍存在较多问题。因此,本文以法律规定为依据,以有关标准和指引为参考,结合团队在数据合规领域的实务经验对有关问题进行简要答复,以期帮助企业理解去标识化并更好地落实“去标识化”措施。
一、什么是去标识化?
答:从去标识化的含义、目的、实现方式、类似定义方面来看:
(一)含义
去标识化是指通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别个人信息主体的过程。我国《个保法》第七十三条第三项、《个人信息安全规范》3.15和《个人信息去标识化指南》3.3均给出了去标识化的定义,具体可参考相应条款。
(二)目的
去标识化的目的是通过降低数据集中的信息和个人信息主体的关联程度,从而提高个人信息处理过程安全性。
(三)实现方式
去标识化的实现方式包括:
①降低信息的区分度,使信息不能对应到特定个人;
②将标识信息和个人的其他信息进行分离,断开信息和个人信息主体的关联。
可采用的技术实现手段包括统计、密码、抑制、假名化、泛化、随机化等(后文有介绍)。
(四)类似定义的比较
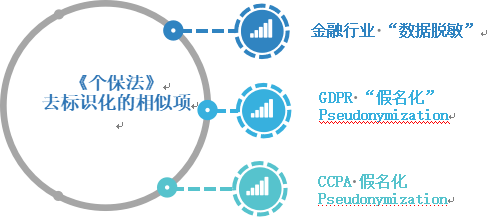
1. 相似定义
(1)与金融行业的“脱敏”相似
《个保法》的“去标识”与金融行业的“脱敏”相似。根据金融行业标准JR/T 0223—2021《金融数据安全数据生命周期安全规范》,“数据脱敏”是指从原始环境向目标环境进行敏感数据交换时,通过一定的方法消除原始环境中数据的敏感性,并保留目标环境业务所需的数据特性或内容的数据处理过程。从定义及处理效果而言,“脱敏”和“去标识化”都是降低数据敏感性但不改变数据原来的属性的安全技术措施。
(2)与GDPR及CCPA的假名化相似
我国《个保法》语境下的“去标识化”内涵与欧盟《通用数据保护条例》(GDPR)的“假名化”(Pseudonymization)和美国《加利福尼亚州消费者隐私法》(The California Consumer Privacy Act,CCPA)的“假名化”(Pseudonymization)相似。
2. 存在区别的定义
(1)与《个保法》的“匿名化”存在区别
二者的本质区别在于即匿名化后的个人信息不再属于个人信息,但去标识化的个人信息仍属于个人信息。
根据《个保法》第四条和第七十三条第(四)项,个人信息不包括匿名化处理后的个人信息,因匿名化处理后的个人信息已无法识别特定自然人且不能复原,该处理过程已改变了原来个人信息的属性。
但个保法并未赋予“去标识化”这样的法律效果。“去标识化”处理是通过安全技术措施降低信息与自然人的关联程度,但未改变原来信息的属性。根据《个保法》第七十三条第(三)项可知,去标识化后的个人信息,在借助额外信息的情况下,仍可识别特定自然人,属于《个保法》第四条个人信息定义中的“可识别自然人有关的各种信息”。


(2)与CCPA的“去标识化”存在区别
CCPA也定义了“去标识化”(Deidentified)并赋予了采取“去标识化”措施的个人信息的处理活动可不受CCPA关于个人信息的有关约束,该规定下的“去标识化”的法律效果与我国《个保法》规定的“匿名化”处理后的个人信息的相似。因此,CCPA的“去标识化”后的个人信息属于非个人信息,这也是其与《个保法》的“去标识化”的主要区别点。

二、“去标识化”后的数据是否仍属于个人信息?
答:在我国,对个人信息采取去标识化技术处理后所得的数据,仍属于个人信息。除非达到了“匿名化”的标准,即满足《个保法》第七十五条第四项规定的,对个人信息采取技术措施后,无法识别特定自然人且不能复原的要求,才属于非个人信息。这样技术处理需彻底不存留或删除个人信息的某些数据属性。
结合实际而言,无论多先进的脱敏 技术都无法达到100%的匿名化。因为只要数据量足够大,同时技术、成本、时间等投入足够多,仍能经过技术处理后,将数据进行复原而再次识别到个人。
因此,即使企业对个人信息采取了“去标识化”技术处理后所得的数据,应当继续归纳为个人信息,并在遵循《个保法》等个人信息保护有关规定的情况下进行数据的处理,同时对这类数据采取相应的保护和管理措施。《深圳数据条例》第二十六条和第七十六条就有涉及相应的规定,要求数据处理者对收集的个人数据进行去标识化或匿名化处理,尤其涉及敏感个人信息处理和向他人提供个人信息的,均应采取去标识化处理,同时与可用于恢复识别特定自然人的数据分开存储。
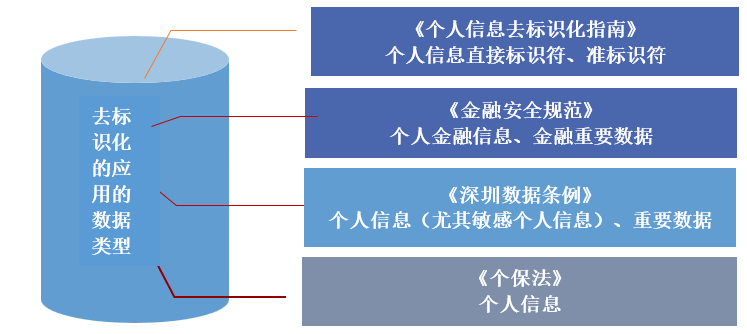
三、“去标识化”活动一般适用于哪些类型的数据?
答:在我国,去标识化活动可适用于个人信息和重要数据。根据《个保法》,个人信息应采取去标识化处理,根据《深圳数据条例》,去标识化适用于个人信息和重要数据,尤其是敏感个人信息;根据《金融安全规范》,脱敏(即去标识化)处理,适用于金融行业的个人金融信息和金融重要数据。
根据我们的经验,“去标识化”活动应重点关注“直接标识符”,尤其是敏感个人信息,同时应兼顾“准标识符”。
根据《个人信息去标识化指南》3.7和3.8条:
|
项目 |
定义 |
示例 |
|
直接标识符
|
在特定环境(个人信息使用的具体场景)下可以单独识别个人的数据属性。 |
姓名、身份号码、护照号、驾照号、地址、电子邮件地址、电话号码、传真号码、银行卡号码、车辆号码、车辆识别号码、社会保险号码、健康卡号码、病历号码、设备标识符、生物识别码、互联网协议(IP)地址号、网络通用资源定位符(URL)等。 |
|
准标识符 |
无法单独识别个人但结合其他数据属性可唯一识别个人的数据属性。 |
性别、出生日期或年龄、事件日期(例如入院、手术、出院、访问)、地点(例如邮政编码、建筑名称、地区)、族裔血统、出生国、语言、原住民身份、可见的少数民族地位、职业、婚姻状况、受教育水平、上学年限、犯罪历史、总收入和宗教信仰等。 |
但企业在明确去标识化对象时,具体需覆盖哪些数据类型、数据集的范围,仍需企业自身的实际情况来处理。企业宜兼顾去标识化后数据的可用性、重标识风险、去标识化的成本和可实现程度等因素,综合制定去标识化目标、对象及方案等。
四、有多少种“去标识化”的方法?
答:《个人信息去标识化指南》附录A,常用的去标识化技术有以下几种:
1. 统计技术,主要包含数据抽样和数据聚合两种技术。
(1)数据抽样:从原始数据集中选取具有代表性的子集来对原始数据集进行分析和评估。
举例:某企业从华南片区300万顾客中随机抽取1万人的4项信息,如性别、生日、地区、消费次数等。因此,即使顾客A的情况完全符合记录1(女,1998年1月1日,深圳,3次),也无法确定记录1就是与顾客A关联的数据。
(2)数据聚合:用求和、计数、平均、最大值与最小值等统计值来对数据进行报告或分析,从而避免披露个体记录。
举例:某企业以深圳市18-35岁女性购买电子产品的平均价格(每年3000元)来标识数据集中每个人的消费价格,记录为(女,1998年1月1日,深圳、电子产品、3000元)。因此,平均消费价格无法单独识别个人,这样的数据对于识别身份主体用处不大。
2.密码技术,主要包括确定性加密、保序加密、保留格式加密、同态加密、同态秘密共享等。
举例:《个人信息去标识化指南》并未提供具体的密码技术例子,而从密码技术领域而言,常见的密码技术包括对称加密算法、非对称加密算法和摘要算法三大类型:
|
密码技术类型 |
例子 |
|
对称加密技术 |
①Data Encryption Standard(DES) ②Triple-DES(3DES) ③Advanced Encryption Standard(AES) ④ RC4、RC5和RC6 |
|
非对称加密算法 |
① Rivest-Shamir-Adleman(RSA) ② Elliptic curve cryptosystem(ECC) ③ Diffie-Hellman ④ Digital Signature Algorithm(DSA) |
|
摘要算法 |
①MD5 ②SHA系列算法 |
3.抑制技术,即对不满足隐私保护的数据项进行删除,不进行展示或发布。抑制技术主要包括屏蔽、局部抑制和记录抑制等三种方式。该技术适用于数值和非数值数据属性,其执行较为容易,且可以保持数据的真实性,也是目前企业较为常用的一个去标识化技术。
举例:
屏蔽:银行的16位卡号信息直接显示为****************。
局部抑制,银行卡的16位卡号信息保留前后四位,中间屏蔽,即XXXX********XXXX。
记录抑制:即发现数据记录中只有1个人的特殊记录的可定位的,则应用抑制技术删除该记录。
4.假名化技术,指一种使用假名替换直接标识(或其他准标识符)的去标识化技术,其包含了独立于标识符的假名创建和基于密码技术的标识符派生假名创建技术两种。
例子:企业从生产库抽取顾客的订单数据进行分析,构建人名字典表,分配常用人名或随机分配假名,代替真实姓名。
5.泛化技术,指一种降低数据集中所选属性颗粒度的去标识化技术,对数据进行更概括、抽象的描述,包括取整、顶层与底层编码。
例子:企业对某地区的会员信息填写时,直接勾选填写的年龄段和收入端,而非实际数据,例如年龄1-18岁,收入0-5000元。
6.随机化技术,指通过随机化修改属性的值,使得随机化处理后的值区别于原来的真实值,包括噪声添加、置换和微聚集。
7.数据合成技术,是一种以人工方式产生微数据的方法,用以标识预定义的统计数据模型。
五、企业如何开展“去标识化”工作?
答:在实施去标识化工作前,企业需做好较多的准备工作,包括但不限于完成内部数据的盘点,即数据的分类分级、个人信息的识别和分类分级,尤其是完成“直接标识符”和“准标识符”的梳理,同时对不同类型个人数据的风险级别评估与确定等基础工作。
因此,结合《个人信息去标识化指南》和我们的实务经验,我们建议按以下的6个步骤开展相应的工作:
1. 数据盘点与风险评估;
2. 确定去标识化的目标;
3. 识别标识;
4. 处理标识;
5. 验证审批;
6. 监控审查。
相比于《个人信息去标识化指南》推荐的去标识化过程,我们建议增加“数据盘点与风险评估”步骤,并将其置于开展去标识化工作的首位。因通过数据盘点调查和风险分析与评判这类基础工作,为企业开展去标识化或者加密等其他一些列的合规管理工作做好铺垫,具体可达成以下的目标:
1. 全面梳理企业内部数据资产,明确数据现状,便于企业明确应进行管控的数据类型、数据范围等,避免去标识化等其他管理工作出现疏漏。
2. 分析并梳理合规管理及技术安全保障措施的现状,有效识别合法、合规性及安全的风险,便于企业根据风险而针对性采取优化处置措施,促进合规目标及成本的合理化,避免企业所采取的措施与企业实际风险不匹配而导致风险未能有效处置等问题。

六、“去标识化技术”的几个常见误区
1.抑制“屏蔽”的“伪脱敏”。伪脱敏指的是仅在前端展示界面对个人信息进行屏蔽或局部抑制,而未在服务器后端进行,即在数据后台仍明文展示和存储个人信息,在数据传输过程中也未做特殊处理,因此在“脱库”或者流量被截获时可能造成个人信息泄漏的风险。
2.暴露个人信息重识别的风险,以及去标识化后的信息存储、访问和使用权限的管理存在瑕疵。例如使用摘要算法加密时,未将原文密文映射表和去标识后的数据进行分开存储,或者使用其他加密技术时,未将秘钥和加密后的密文分开存储,同时内部对于秘钥等可以重识别个人的标识符访问、使用等权限管理不严格,未做最小化管理或未严格执行权限审批工作,导致数据安全泄露风险。
3.缺乏审计和监督。内部对于去标识化技术的应用,未定期开展审计和监督,包括去标识化处理有效性的审计和监督以及安全风险排查等。这是企业安全合规工作未形成闭环,导致虽采取了去标识化措施,但未到达有效保护数据安全预期效果的常见问题。
作者:许瑞凤
审稿:南红玉
(文中观点不代表北源律师事务所的观点或法律意见)