




摘要
2021年12月21日,国务院办公厅发布《要素市场化配置综合改革试点总体方案》,明确提出要探索“原始数据不出域、数据可用不可见”的交易范式,在保护个人隐私和确保数据安全的前提下,分类分级、分步有序推动部分领域数据流通应用。个人信息保护不仅仅需要健全完善的法律法规与执法机制,信息技术的发展在其中也有着不可或缺的地位。
隐私计算技术就是实现“原始数据不出域、数据可用不可见”的一个重要技术路径,有望在合法合规的前提下促进数据流动。[1]
隐私计算是面向隐私信息全生命周期保护的计算理论和方法,是隐私信息的所有权、管理权和使用权分离时隐私度量、隐私泄漏代价、隐私保护与隐私分析复杂性的可计算模型与公理化系统。
目前主流的隐私计算技术主要有三个方向:联邦学习、可信执行环境与多方计算。
一、联邦学习(Federal Learning)
联邦学习的目的在于建立一个分布式的机器学习训练模型。在训练过程中,训练参与方依据数据来源对任务进行分解,不同节点在本地利用自己的数据资源进行分布模型算法训练,并交换训练模型数据。因此联邦学习下,参与者仅仅交换模型信息(主要是梯度等参数),不涉及个人信息本身的共享与转让,从而确保在保护数据隐私的前提下,完成算法模型训练的目的。
根据训练数据在不同参与方之间的数据特征空间和样本ID空间的分布情况,联邦学习可以分为横向联邦学习、纵向联邦学习与联邦迁移学习。
(一)横向联邦学习(Horizontal Federated Learning)
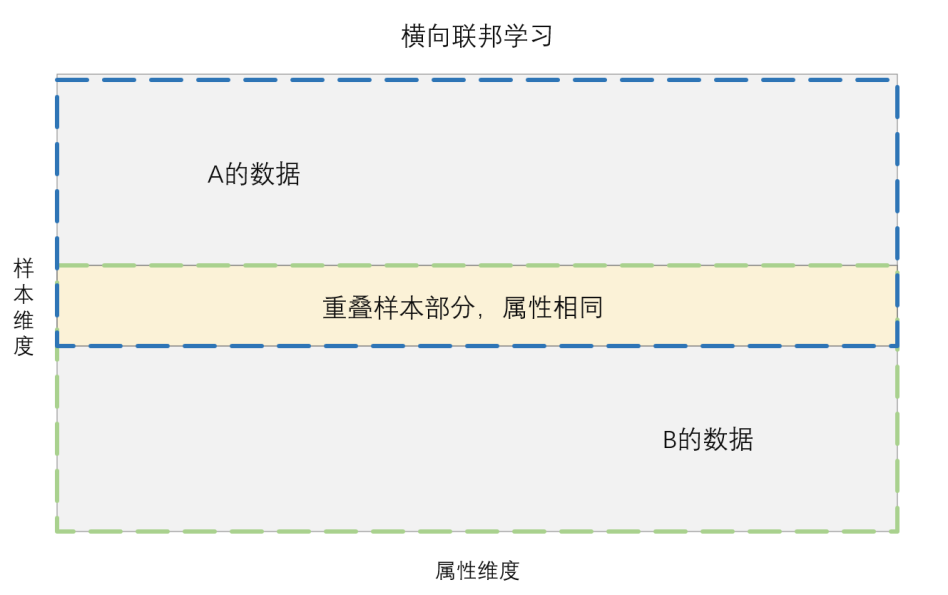
横向联邦学习是指联邦学习参与方手中的数据字段有重叠或相同,但是各参与方手中所拥有的数据样本不同。比如一家全国性银行在全国均设有分行,每个分行手中掌握的个人信息的特征或字段均相同,但用户类型或数据样本不同。因此横向联邦学习可以解决单个主体手中数据样本数量不足的问题。
(二)纵向联邦学习(Vertical Federated Learning)
纵向联邦学习与横向联邦学习相反,是指各参与方手中的数据样本或者数据主体相同,但是数据特征或字段不同。如同一地区某一家银行与某一家商场的客户可能重叠,但这些重叠用户的数据特征或者说字段可能存在很大的差异。

(三)联邦迁移学习(Federated Transfer Learning)
联邦迁移学习则是指各参与方之间数据样本与数据特征重叠均非常少的场景,如A地银行与B地商场之间的用户数据,既没有用户重叠,也没有数据特征重叠。

《个人信息保护法》对数据共享提出了严格的合规要求,特定的告知内容、单独同意与数据安全的高标准,都要求企业投入较高的合规成本。传统的机器学习模式必须将数据(包括个人信息)汇聚在中心节点后才能进行训练。通过联邦学习技术,不同节点可以在本地进行模型算法训练,而无需与将个人信息共享至中心节点,可以有效避免个人信息共享带来的合规风险,因此在金融风控、医疗诊断、政府公共数据共享等领域具有较为广阔的应用前景。
二、可信执行环境(Trusted Execution Environment)
可信执行环境是指在一个安全的软件或者硬件环境中,通过时分复用CPU或者部分内存地址划分等技术,构建一个接近于绝对安全的区域,即将系统软硬件资源换分为可信执行环境与普通执行环境两个执行环境,并确保两个执行环境安全隔离,从而各参与方可以将其所有的敏感数据加密后传输至该区域内进行计算。相比多方计算与联邦学习等隐私计算技术,可信执行环境具有如下几点优点:第一,通用性强,使用方无需对已有的算法进行更改,仅需进行计算环境迁移;第二,性能优异,可信执行环境技术的性能是上述隐私计算技术的数倍,此外,可信执行环境还可以通过硬件对其进行加速。
目前可信执行环境的主要实现方式为硬件方式。国外较为成熟的有ARM平台的TrustZone、AMD的SEV和Intel旗下的SGX,国产芯片厂商如兆芯、海光、飞腾、鲲鹏也能提供相应功能。
虽然可信执行环境能够为隐私计算提供安全的运行环境,但是从法律合规的角度来看,其本身并未解决数据共享的困境。在技术层面虽然是可信安全的执行环节,但是在法律层面仍然属于个人信息的共享,因此相应的合规义仍然应当注意遵守。
参考文献:
[1].李凤华,李晖,牛犇:《隐私计算理论与技术》,人民邮电出版社2021版,第49页。
作者:广东北源律师事务所数据合规团队
(文中观点不代表北源律师事务所的观点或法律意见)