




法律法规对数据安全能力要求
(一)法律法规对数据处理的技术性要求
1
原则性要求
我国与数据处理相关的法律法规最主要集中在《数据安全法》(第27条)与《个人信息保护法》(第9条)以及《网络安全法》(第42条),还有《民法典》(第1038条)和《全国人民代表大会常务委员会关于加强网络信息保护的决定》(第4条)。
基于上述法律法规,总结出了一些比较原则性的要求:
1、采取技术措施和其他必要措施,确保其收集、存储的数据、个人信息安全,防止信息泄露、篡改、丢失。
2、发生或者可能发生个人信息泄露、篡改、丢失的,应当及时采取补救措施。
2
具体要求
(1)加密、去标识
法律条文:
■《个人信息保护法》第51条
■《深圳经济特区数据条例》第76条
可参考标准:
■GB/T 36624-2018《可鉴别的加密机制》
■GB/T 31503-2015《电子文档加密与签名消息语法》
■GB/T 37964-2019《个人信息去标识化指南》
(2)数据分类
法律条文:
■《网络安全法》第21条
■《深圳经济特区数据条例》第77条
可参考标准:
■GB/T 38667-2020《信息技术 大数据 数据分类指南》
■GB/T 37973-2019《大数据安全管理指南》
■JRT 0197-2020《金融数据安全 数据安全分级指南》
■TC260-PG-20212A《网络安全标准实践指南一网络数据分类分级指引》
(3)权限管控
法律条文:
■《个人信息保护法》第51条
可参考标准:
■GB/T 41817-2022《个人信息安全工程指南》
(4)应急预案及处理
法律条文:
■《个人信息保护法》第51条
■《网络安全法》第25条
■《数据安全法》第23条、第29条
■《深圳经济特区数据条例》第85条、第86条
可参考标准:
■GB/T 35273-2020《个人信息安全规范》
■GB/T 40652-2021《恶意软件事件预防和处理指南》
■GB/Z 20986《信息安全事件分类分级指南》
■GB/T 38645-2020《网络安全事件应急演练指南》
(5)防病毒和网络攻击、网络侵入
法律条文:
■《网络安全法》第21条
可参考标准:
■GB/T 20275-2021《网络入侵检测系统技术要求和测试评价方法》
■GB/T 30276-2020《网络安全漏洞管理规范》
■GB/T 20281-2020《防火墙安全技术要求和测试评价方法》
(6)网络运行状态监测、网络安全事件监测
法律条文:
■《网络安全法》第21条
■《数据安全法》第29条
■《深圳经济特区数据条例》第83条
可参考标准:
■GB/T32924-2016《网络安全预警指南》
(7)网络日志留存
法律条文:
■《网络安全法》第21条
■《深圳经济特区数据条例》第75条
可参考标准:
■YD/T 3641.2-2020《互联网访问日志留存技术要求》
(8)重要数据备份加密
法律条文:
■《网络安全法》第21条
■《深圳经济特区数据条例》第78条
可参考标准:
■GB/T29765-2021《数据备份与恢复产品技术要求与测试评价方法》
(9)网络安全等级保护义务
法律条文:
■《网络安全法》第21条
■《计算机信息系统安全保护条例》第9条
■《数据安全法》第27条第1款
可参考标准:
■GB/T22239-2019《信息安全技术网络安全等级保护基本要求》
3
特殊要求——征信信息
征信信息除了遵从法律法规的有关规定,不同行业也会进行不同限定。《征信业务管理办法》以及《个人信用信息基础数据库管理暂行办法》都提出了更高要求。例如,它提出征信的保存期限提升至5年,同时还指出需要三级或者三级以上的网络安全等级保护能力,对于系统物理安全、通信网络安全、区域边界安全、计算环境安全以及管理中心安全都远高于其他规定。
(二)GDPR中的技术性要求
一般数据保护条例(GDPR)为欧洲联盟于2018年5月25日出台的条例,前身是欧盟在1995年制定的《计算机数据保护法》。GDPR为欧盟公民数据处理制定了一套统一的法律和更严格的规定,也规定了对违规行为的严厉处罚。
Article 5(1)(f)规定个人数据应“以确保个人数据适当安全的方式进行处理包括使用适当的技术或组织措施(using appropriate technical or organizational measures)防止未经授权或非法处理,以及防止意外损失、破坏或损害”(“完整性和保密性”)
Article 32对第5(1)(f)条进行了扩展,规定了安全原则的实际要求,并列举了具体的措施内容:
1、the pseudonymization and encryption of personal data(个人数据的匿名化和加密)
2、the ability to ensure the ongoing confidentiality, integrity, availability and resilience of processing systems and services(确保处理系统和服务的持续机密性、完整性、可用性和弹性)
3、the ability to restore the availability and access to personal data in a timely manner in the event of a physical or technical incident(在发生物理或技术事件时及时恢复个人数据的可用性和访问权限的能力)
4、a process for regularly testing, assessing and evaluating the effectiveness of technical and organizational measures for ensuring the security of the processing(定期测试,评估,同时评估技术和组织措施的有效性,以确保处理过程的安全性)
(三)ICO对于数据处理的判断标准
英国信息专员办公室(Information Commissioner’s Office) 同样表示并没有定义数据控制/处理者应该采取的安全措施,它要求数据控制/处理者拥有与其的处理所带来的风险“相适应”的安全水平,对水平的判断因素如下:
1、评估评估数据的价值、敏感性或机密性;
2、如果数据被泄露可能造成的损害;
3、数据处理场所和计算机系统的性质和范围;
4、拥有的员工人数以及他们访问个人数据的频率;
5、数据处理者持有或使用的任何个人数据。
同时,ICO也建议定期进行措施的有效性测试,在技术上可利用漏洞扫描和渗透测试进行压力测试。ICO认为可适用的技术类措施如下:
1、对所有处理个人数据的可用设备(包括终端用户设备和可移动媒体)进行跟踪和记录;
2、通过适当地配置技术,最大限度地减少可用的服务和控制连接,将攻击的机会降到最低;
3、积极管理软件漏洞,包括使用支持性软件和应用软件更新政策(打补丁),并在无法应用补丁时采取其他缓解措施;
4、管理终端用户设备(笔记本电脑和智能手机等),以便对与个人数据互动或访问个人数据的软件或应用程序进行组织控制;
5、对不受物理控制的设备(笔记本电脑、智能手机、可移动媒体上的静态个人数据以及对以电子方式传输的个人数据进行加密;
6、确保网络服务受到保护,避免出现常见的安全漏洞,如SQL注入和知名媒介(如OWASP Top 10)中描述的其他漏洞。
数据全生命周期技术性合规要点
(一)技术视角下的数据处理生命周期
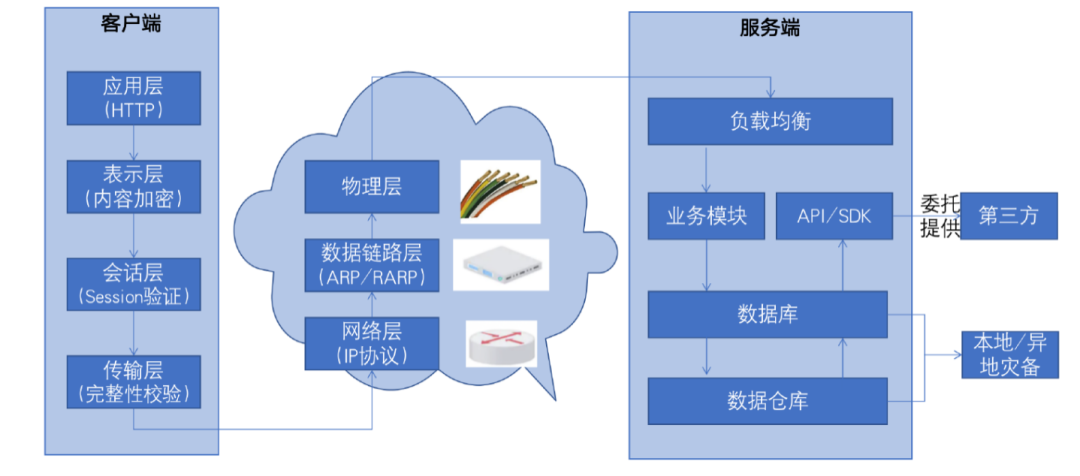
上图为简化版的数据处理流程,左侧的客户端可以理解为APP,当数据在APP里产生之后,它会通过网络层面传输至企业的服务器。在企业服务器,数据会经过图中所述环节进行相应的业务处理。同时由于业务需求,可能会涉及到提供或委托给第三方。这三部分就是常规的数据处理过程。
首先,在客户端会有一个应用层,它最主要是提供相应的服务,会使用不同的协议。例如通过 PC浏览器访问不同网页,就是使用了HTTP 的协议。表示层的功能包括数据加密,和非结构性数据的格式转化,例如图片。会话层的功能是与服务器建立一个虚拟通道,进行身份识别,例如客户端会从服务端得到一个session ID去验证是否经过服务端授权认可。身份认证通过之后,就会进入传输层。传输层主要完成数据切割和校验完整性,受限于传输带宽大小和从效率考虑,它会把一个数据段切割为多个数据包传输,并进行完整性校验,如某个数据包丢失,则只需重发该数据包而不用整个数据段。在这一层面最主要使用TCP 和 UDP协议,分别用于支持可靠和不可靠的连接。同时这个层面还出现一个新的概念——端口,相当于邮寄过程的门牌号,端口可自定义或使用缺省值,例如http端口的缺省值则为80。
其次,在网络层,最主要是路由选择的功能,类似于如何选择最短、最快的网络路径完成数据传输,可想象快递物流中的途径节点。数据链路层最主要是把IP地址转化成Mac地址,相当于将邮编转化为具体的城市、区、乡镇。物理层则可理解为现实中的光缆(或网线),用于物理讯号传输的介质。
最后,当数据经过网络传输达到企业的服务器时,一般会进入负载均衡。负载均衡主要解决海量请求并发的问题,背后是服务器集群,数量庞大的服务器。负责均衡根据服务器的可用状态,分配至具体的应用服务器进行业务处理。业务模块处理完成后,一般会进入数据库进行存储,很多时候企业到这一步就结束了,但是随着数据应用场景(如用户个性化推送)的不断发展,很多企业都会使用数据仓库进行数据挖掘。数据仓库从数据库中拉取相关的数据,通过算法或特定程序进行新数据的生成,例如用户画像、用户标签等。数据仓库会将这些数据重新存入到数据库,以提供业务或应用使用。例如,采取API 或SDK的方法提供给第三方。另外,根据法律法规要求,对于重要数据或数据库需履行容灾备份的义务。
以上,就是从技术底层理解数据处理的生命周期,具备该种思维能帮助我们在确定评估对象或者评估范围时不容易遗漏要点。例如,表示层则可能会有数据在本地留有缓存的问题,负载均衡背后的服务器之间数据的一致性问题,数据仓库的算法应用和管控问题,通过api或sdk明确供应商对象以及委托或提供关系。
(二)法律视角下的数据处理生命周期
1
收集环节
收集环节主要是收集信息的过程,会有合法性基础的问题。通过告知与同意解决合法性基础问题。而合规接口往往是避免非法收集个人信息的主要方式,合规接口会查看授权日志,查看准备要收集的个人信息有没有得到授权。如果得到授权,才会把权限开放给收集功能模块。违反最小必要原则的解决方法可以建立黑名单,或者白名单,通过记录APP所收集的所有字段类型进行记录,并有一个是否允许收集的标记。通过云端策略的下发,能够更好控制收集范围,履行最小必要的义务。
2
传输环节
传输加密和完整性校验。加密分为内容加密和通道加密,使用对称性或非对称性算法属于内容加密,使用加密协议(例如https)则为通道加密。内容加密还区分字段级加密、文件加密、文件夹级加密,可根据所处理的数据的敏感性进行择一。
3
存储环节
存储最主要是要分类,在法律层面它没有一个很明确的要求,可以参考相关的行业标准,例如JRT 0197-2020《金融数据安全 数据安全分级指南》。其次,是全量备份。虽然法律法规只针对于重要数据和重要数据库进行容灾备份。但在无法区分或定义出重要数据前,进行数据的全量备份,则可一劳永逸。
4
使用和加工
使用和加工最主要在三点,一个是建立特征库进行违法和不良信息内容识别和清理;第二是进行全流程的日志记录、留存和备份,以实现可追溯性。第三是进行专项合规,例如算法合规和管理。
5
委托提供
在委托关系层面,作为数据处理者有义务审查第三方是否履行等同的安全技术,可要求根据业务特点要求第三方提供证明材料,例如ISO认证、SOC认证、等保等。
6
跨境环节
跨境需特别注意出境申请申报以及国家组织的安全评估,要注意申报和评估要求的时间点。
7
删除环节
删除可分为物理删除、逻辑删除和销毁。在金融行业体现的更为明显,删除需要达到销毁程度,普通业务达到物理删除即可。
典型数据处理场景的技术问题探讨
(一)数据爬虫
网络爬虫,也叫网络蜘蛛,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,其目的一般为编篡网络索引。
爬虫的流程一般如下:
首先访问并解析robot协议,该协议规定了内容是否允许爬取,如果爬取目标在允许范围内,则下一步构造访问身份和请求。构造完毕将获取 URL 的队列,按爬虫策略访问指定的URL并发送请求 ,服务器收到请求后将返回HTML/XML资源。在得到资源后就可以做特征解析和提取,最后进行数据存储。所以爬虫就是一个发送请求,获取资源的过程。
在爬虫的过程中,我们需要做的合规有以下几点:
第一是Robot协议。它是一种互联网行业的一个通用规范而非法律法规,但是如果违反了该协议,法院将认定存在违规的抓取行为,无异于非法侵入,可能侵犯他人权益,导致行为违法。所以如果在爬虫过程中不遵守该协议,可能将导致不当行为的认定。Robot协议的文件基本公开,只需要在域名后加上/robots.txt路径即可查看。其中,Disallow的内容不允许爬取,相应地Allow的内容允许爬取。
第二是爬虫的user-agent身份说明。user-agent主要是用于网站识别客户端的身份是自然用户还是爬虫,为避免爬虫在未经网站拥有者的允许下侵犯网站的权益,user-agent需要表露本身的爬虫身份,而不能模拟或使用虚假的自然人身份。
第三是频率和流量控制。过高频次的流量或请求,容易导致DDos 攻击,涉嫌计算机破坏行为。另外,例如加密、限制访问请求或限制访问时段等技术措施也是不可绕开的,否则爬虫行为可能存在不正当性。
(二)常见算法类型
常见的算法类型,主要根据算法管理条例所进行列举。
第一,生成合成类。主要是自动生成视频内容、 VR和语音识别等技术。
第二,个性化推荐类。个性化推荐与内容和营销有关,而营销是企业获得利润的重要来源,所以个性化推荐在公司中是非常普遍的功能模块。
第三,排序精选类。可以简单理解为微博热搜,根据热度访问量、点击量和收藏量等维度来计算权重,再根据权重进行排序。算法逻辑并复杂,但它更多是一种公共用户的行为表示。
第四,调度决策类。根据现有的数据进行优化,测推测出未来时间的路线变化,以更好地进行决策和调度,存在一定特殊性。
第五,检索过滤类。常用于搜索引擎,去重、垃圾信息过滤等都属于检索过滤类。
重点在于个性化推荐类,因为它在企业的营销上具有通用性。
个性化推荐一般来说有两类技术,协同过滤和回归测试。协同过滤有两种,第一种情况是基于User,另一种情况是基于Item。
(1)协同过滤:
假设用户A喜欢游戏1,2,3;用户B喜欢游戏1,2,4;用户C喜欢游戏1。
基于User:判断A和B相似,则向A推送游戏4。
基于Item:A和B都喜欢游戏1和游戏2,判断喜欢游戏1的也会喜欢游戏2,则向喜欢游戏1的用户C推送游戏2。
(2)回归预测:
算法根据拟合函数进行处理,分析和确定影响结果的一个或多个因素。
算法合规的要点:
一、理清算法、算法推荐服务和自动化决策。算法是一系列的程序的解决方案,但是算法推荐服务是法律层面上的意义,即使用以上列举的 5 类推荐技术,通过互联网向用户提供信息的服务叫做算法推荐服务。自动化决策是利用程序进行分析评估并决策。算法推荐服务并不一定是自动化决策,需要注意三者的差异,以更好地界定合规义务。
二、算法结果质量评估。质量评估更多是一种验证,算法结果可能有错误,此时需要保证其质量。若期望值与样本偏离太大,则算法质量存在问题。
三、算法输入输出的内容治理。算法是一种技术工具,一套数学函数的运算,本身不具有利害属性,但是标签是人为引入,标签即内容,内容就需要进行治理,所以要对输入和输出环节进行内容治理。
四、可追溯性。可追溯性是比较重要的问题。一方面法律法规中存在对其要求,另一方面从已知的监管案例可以说明其重要性,监管单位检查算法主要是通过日志追溯整个过程。
(三)网络日志
日志是系统或者业务过程中所产生的记录,被保存的记录能够帮助验证尽调的内容,能够避免企业自身风险的问题,同时避免风险出现时与第三方的责任比例问题。
日志主要分为用户行为日志、业务变更日志以及系统运行日志。
在技术层面,日志有几个分类,一个是info信息,只是记录一个一个服务器、系统的运行状态。还有warn警告,当发现有不合规操作或者系统突然超过流量,它可能就会警告。第三个是错误,功能模块存在一些 bug 或者问题,它就会报错。debug是一个调试,定位或者解决系统问题的过程中,需要去看调试的技术是否能够解决这个问题,它会产生数据来作为调试的参考。
网络日志在数据合规工作中的作用有:
1、核验收集和提供是否符合必要性
2、核验传输通道、内容加密方式
3、核验源地址和目标地址,识别第三方和传输方向
4、核验全链路的可追溯性
(四)地理围栏
地理围栏是指通过硬件设备或安全策略等技术措施虚拟出一个物理范围,限制或隔离该范围内的数据处理活动,使之符合数据处理相关法律法规的要求。
地理围栏的常见应用场景包括:
1、视频流产品场景
2、消息推送场景
3、无人机禁飞
4、物联网安防
但地理围栏也有其局限性,如地理围栏的准确度问题,又比如用户提供虚假的地理位置。
来源:iLaw合规